Pendant les séances du 7 et 14 Nov, nous avons continué à travailler sur le script du tableau html à partir des listes d’urls que nous avons établies sur notre thème ‘Bonheur au travail’.
Tout d’abord, nous avons complété tous les traitements reste à faire dans le programme des séances précédantes.

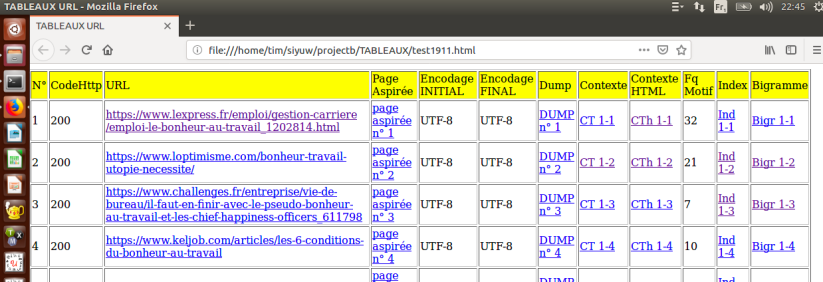
En complétant le script du traitement, avec les colonnes ajoutés de ‘Contexte‘, ‘Index‘ , ‘Fréquence Motif‘ et ‘Context html minigrep‘, nous avons aussi ajouté des colonnes ‘Encodage Initial‘ et ‘Encodage Final‘ pour se rendre compte plus clairement quel url a été traité par iconv.
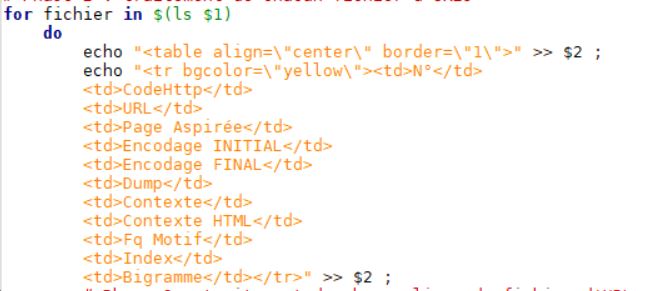
Et puis le traitement:
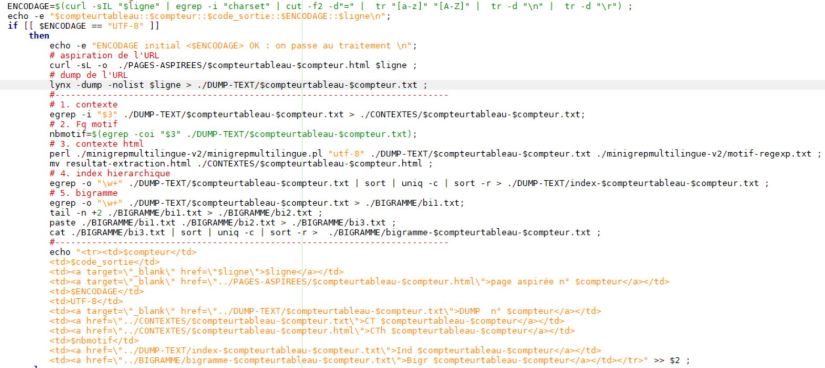
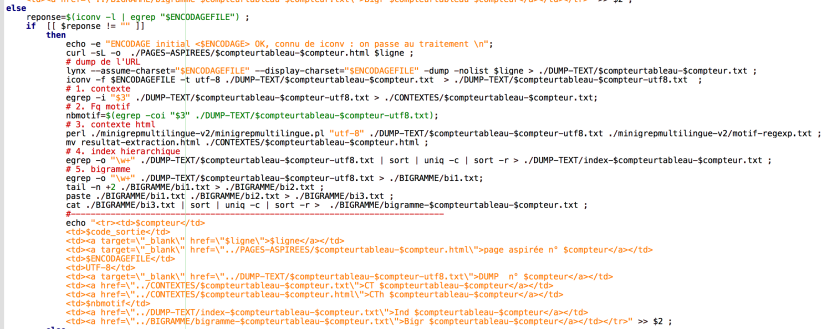
Pour le minigrep, il faut bien vérifier le nom du répertoire utilisé et il faut définir le parametre dans le fichier motif-regexp.txt pour pouvoir construire un contexte html.
En exécutant le programme, on peut voir qu’est-ce qui se passe avec les indications ‘user-friendly’ du programme.
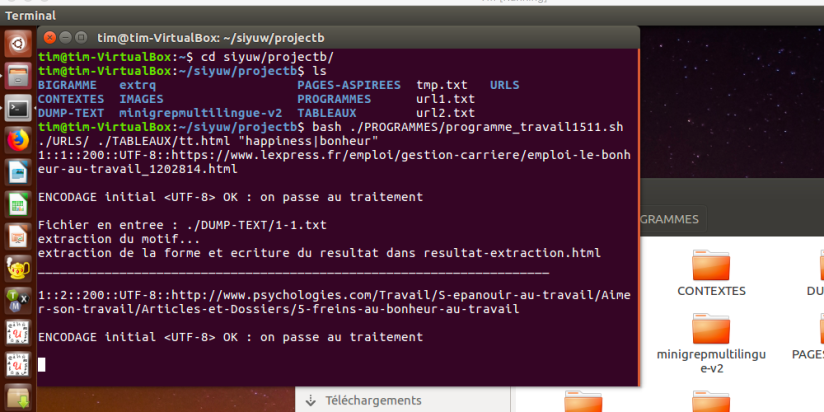
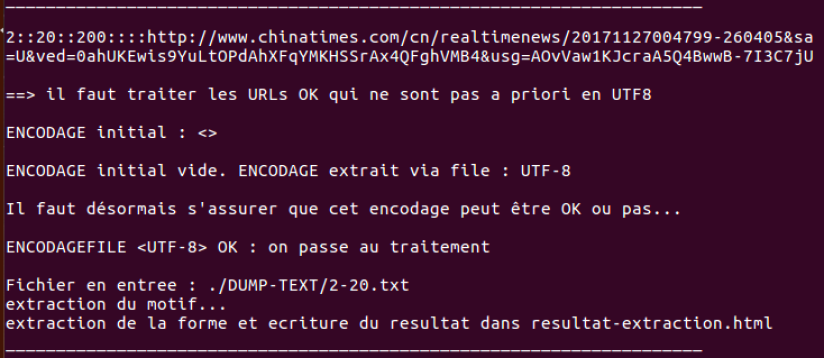
Et puis le résultat du tableau final:
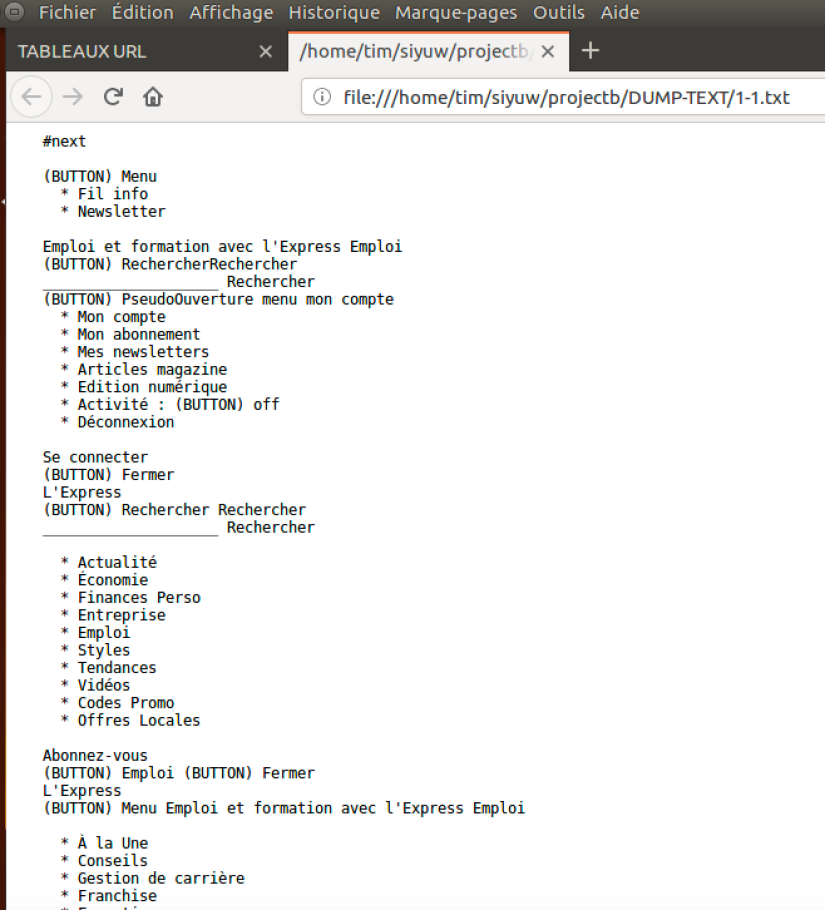
Voici la page de ‘Dump‘:
La page de ‘Contexte html‘:
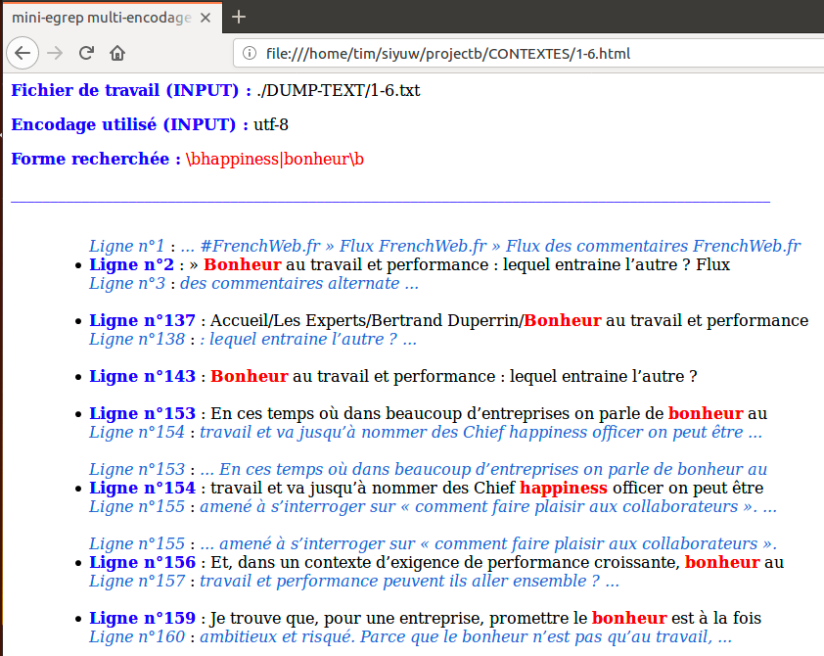
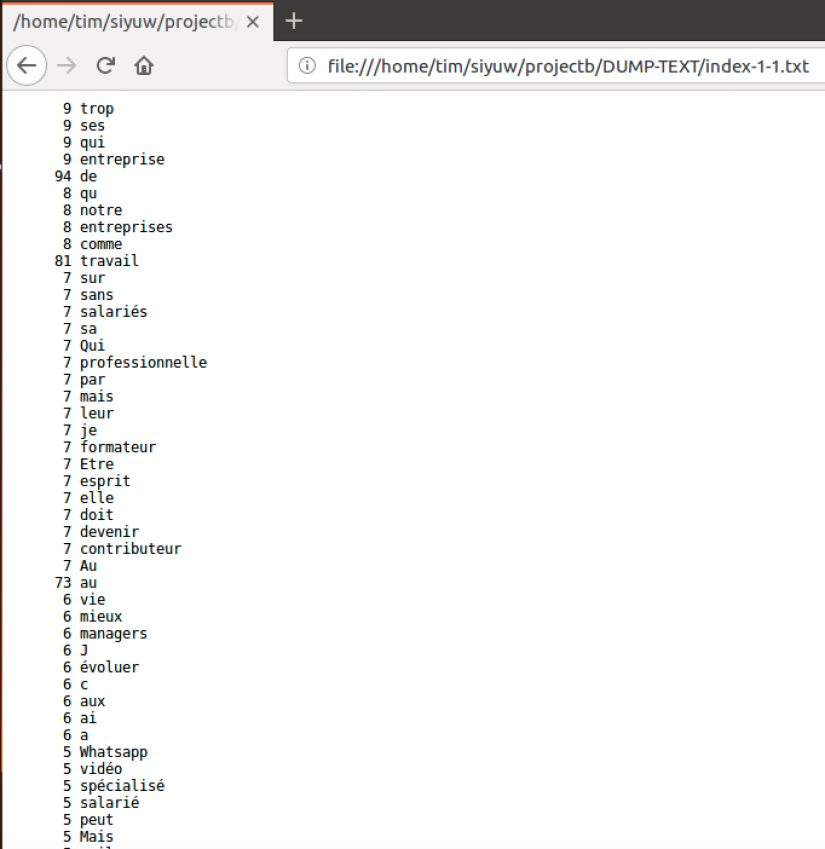
La page de ‘Index‘:
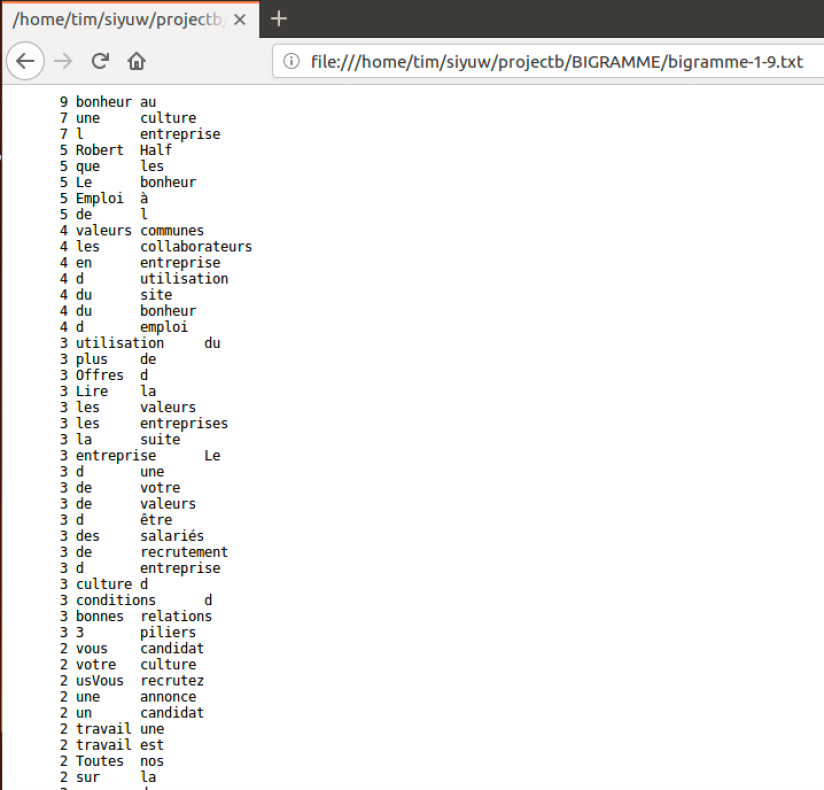
La page de ‘Bigramme‘: (Comme nous traitons un syntagme qui contient 3 mots, il faut qu’on modifie la partie Bigramme, peut-être en quadramme par exemple.)