
Lors de la séance du 28 Nov, nous avons commencé la phase 2 de notre projet — l’ analyse du corpus, avec les outils des nuages des mots et l’iTrameur (outil d’exploration des données).
Tout d’abord, il y a plusieurs outils pour créer le nuage des mots: Wordle, Word Cloud Generator, WordItOut, etc. Ici, nous avons utilisé WordItOut pour créer les nuage des mots.
On copie-coller le corpus de contexte en français dans la fenêtre de génération du nuage.
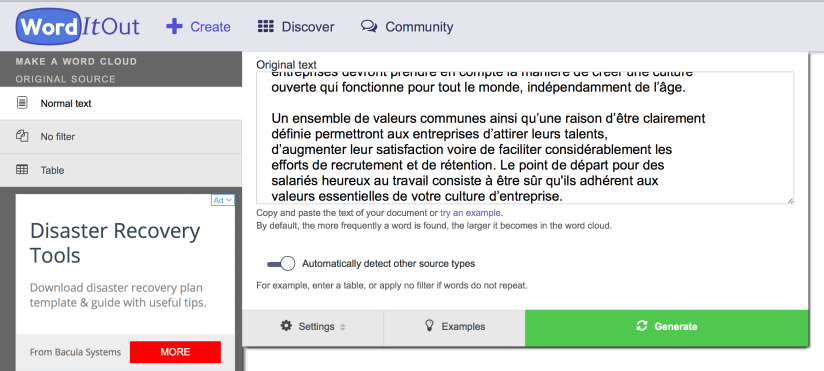
Puis, on modifie les paramètres pour établir une liste de stop-words.
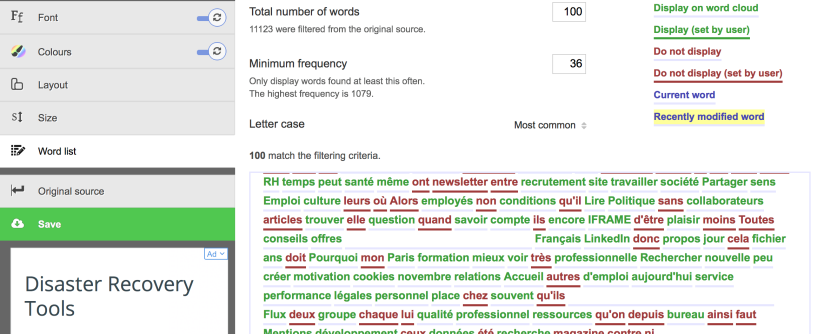
Et puis voilà le nuage des mots.

• Pour l’iTrameur, nous avons aussi essayé avec un corpus de contexte en français.
Tout d’abord il faut upload le fichier en indiquant le délimiter séparateur, ici on peut le laisser vide car c’est séparé par ligne par défaut.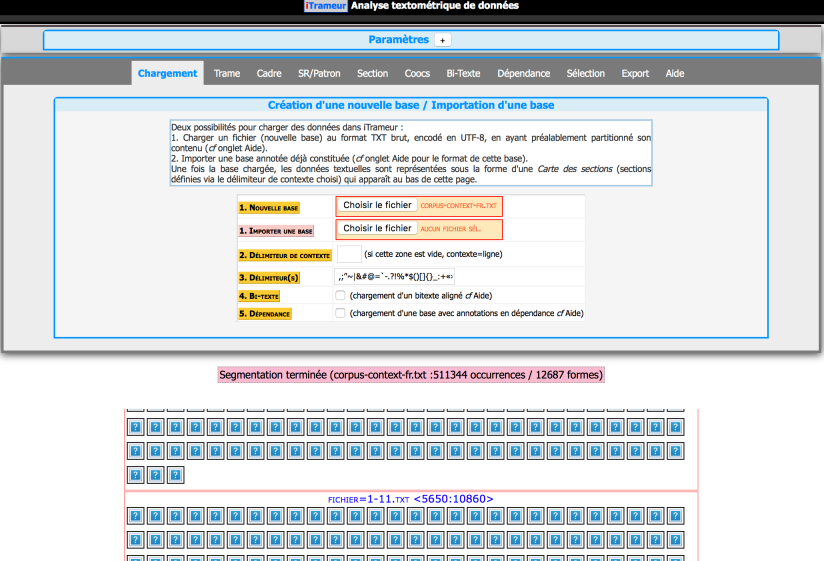
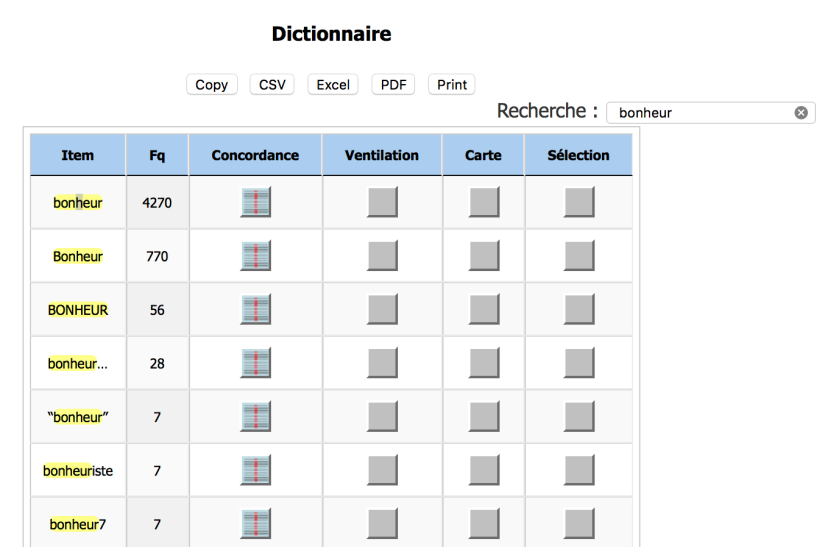
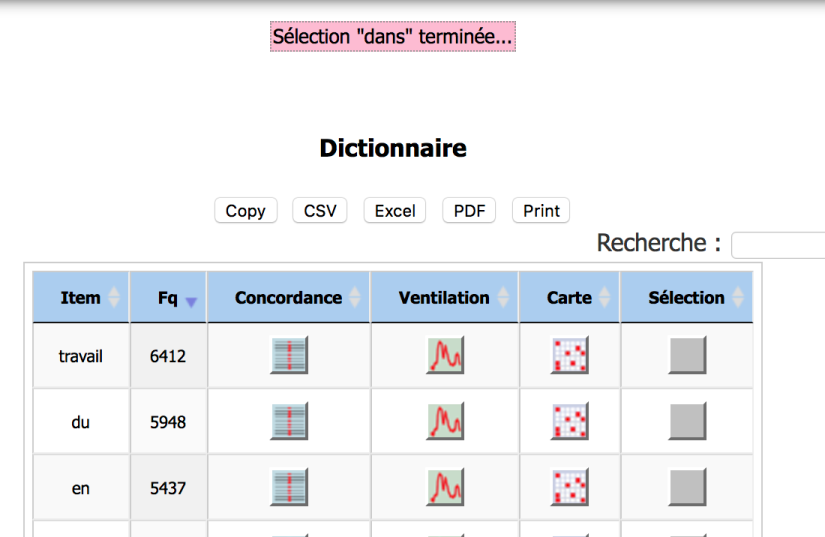
On peut regarder les occurrences des mots recherchés via le botton Dictionnaire.
Les segments répétés:
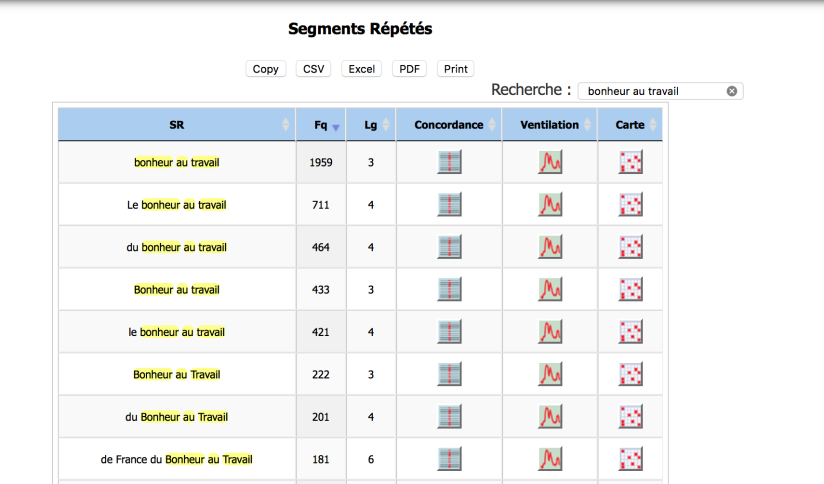
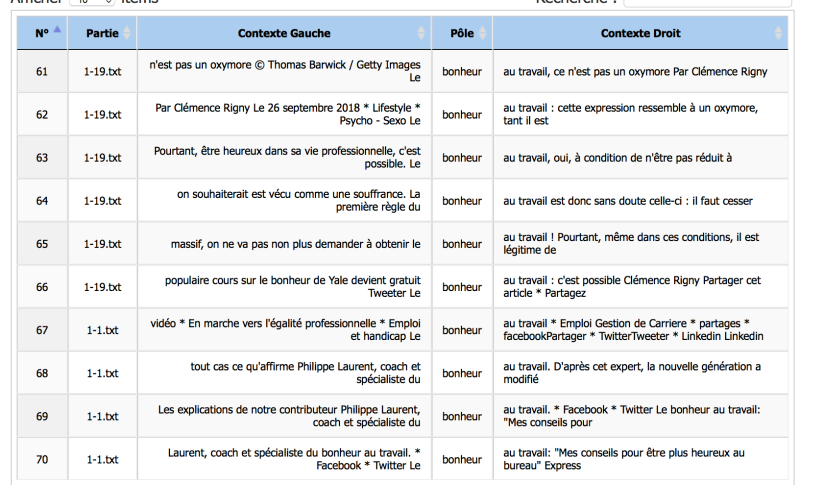
Les contextes:
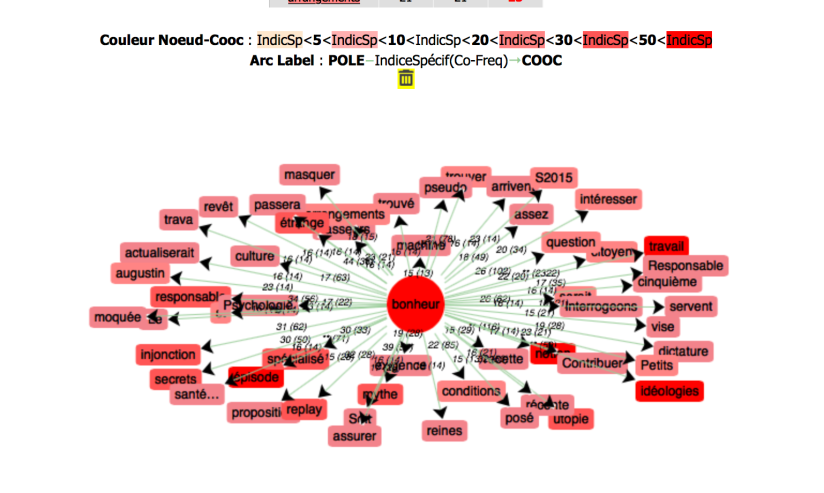
Lors qu’on calcule des concurrences ( Coocs ), on peut aussi sélectionner des mots pour les mettre dans la stop-liste et paramétrer l’affichage, ce qui est très utile quand on traite avec un grand corpus… pour ne pas planter la machine…
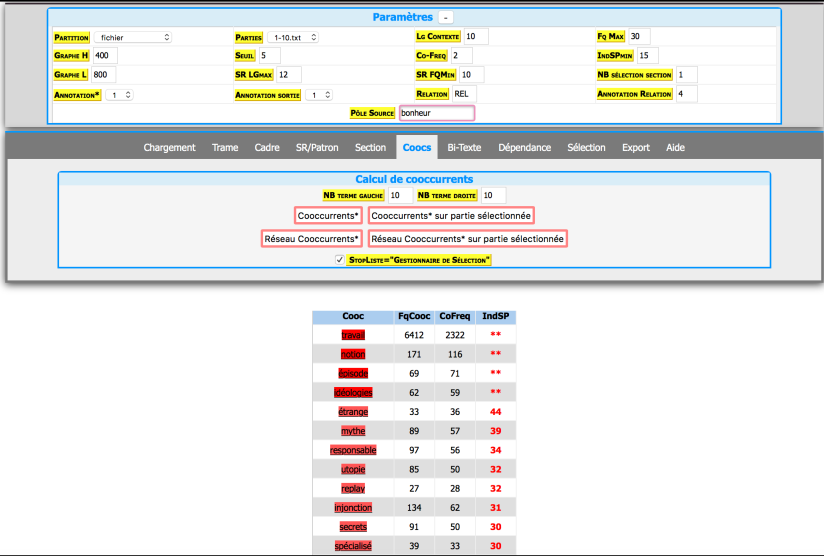
Et voilà le schéma du mot recherché “bonheur”:
Il reste encore beaucoup à découvrir sur le Trameur et l’iTrameur.
