
Cette semaine, nous repartons du script vu lors de la séance précedente pour le finaliser. Jusq’au maintenant, notre script contient non seulement les traitements à faire sur les URLs initialement codées en UTF-8 mais aussi la conversion (avec la commande iconv) et le traitement des URLs non UTF-8. Pour chercher l’encodage des URLs, nous avons utilisé les commandes curl et egrep. En appliquant la commande file sur la page aspirée, nous avons également recherché l’encodage de la page.
Pendant cette séance, nous avons ajouté la possibilité de rechercher l’encodage de la page aspirée en utilisant egrep. Voici le code:
egrep “meta.+charset *= *[^>]+” ./PAGES-ASPIREES/$compteurtableau-$compteur.html | egrep -o “charset *= *[^>]+” | cut -f2 -d”=” | egrep -o “(\w|-)+”
Tout d’abord, pour chaque fichier de page aspirée, nous cherchons le string représenté par l’expression regulière “meta.+charset *= *[^>]+”. La balise meta contient des informations sur la page HTML y compris l’encodage. Ensuite, nous ne prenons que la partie “charset *= *[^>]+” que nous coupons avec le délimiteur “=”. Nous prenons la deuxième colonne et finalement nous gardons juste les caractères alpha-numériques et le ‘-‘ et cela nous donne l’encodage de la page aspirée en utilisant egrep.
Nous avons incorporé cette partie dans notre script, ce qui nous mène à l’achèvement du script. Nous arrivons à la fin de la phase 1 du projet. Avant, de passer à l’étape suivante, il va être nécessaire de préparer des corpus pour l’analyse: un à partir des fichiers CONTEXTES construits dans le tableau avec le minigrep et un à partir des fichiers DUMPs.
Avec quelques commandes de bash, nous avons crée les deux fichiers pour chaque langue: contextes_concat_[lang].txt et dump_concat_[lang].txt.
Voici le script pour regrouper tous les fichiers CONTEXTES (d’une même langue) dans un fichier:
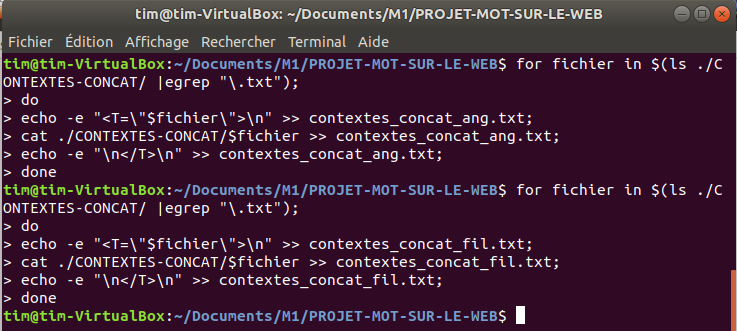
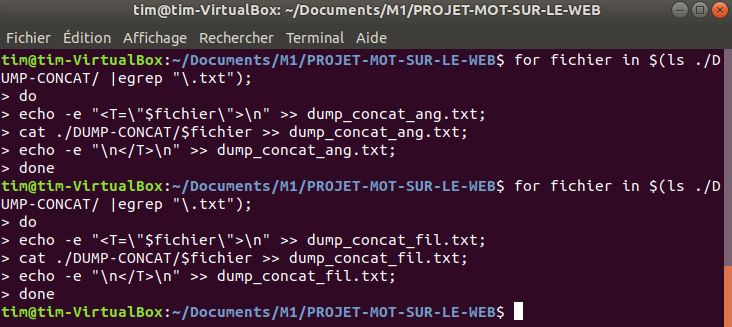
et le script pour regrouper tous les fichiers DUMPS (d’une même langue) dans un fichier:
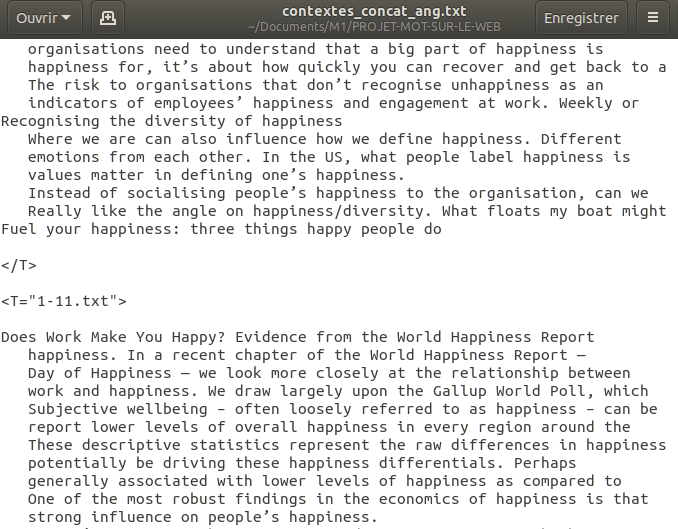
Voici une image montrant les marqueurs de début et de fin des fichiers CONTEXTES regroupés dans un seul fichier, en format texte brut.
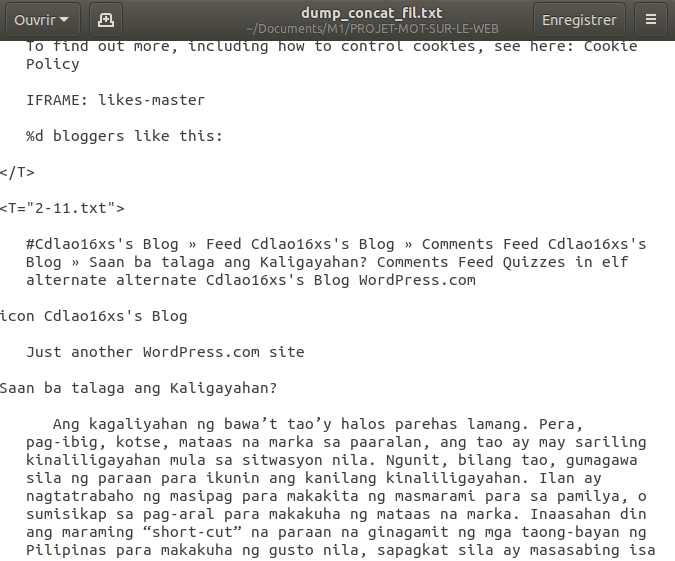
Et voici une image montrant les marqueurs de début et de fin des fichiers DUMPs regroupés dans un seul fichier, en format texte brut.
Avec le contextes_concat, nous pouvons regarder les détails avec un contexte réduit autour du mot/syntagme choisi. Au même temps, nous considérons tout le texte contenant le mot/le syntagme avec le dump_concat. Ces deux fichiers nous permettent d’avoir deux types de texte qui correspondent à 2 manières de décrire le contexte des mots dans ces textes. Nous pouvons commencer à examiner les contenus de nos corpus.

Vous y êtes presque !
Reste à analyser vos données avec iTrameur !
LikeLike