

Pour le corpus de chinois, il est impossible de le traiter dans la même façon qu’on a fait avec les autres langues, car les fichiers de dump des urls chinois ne sont pas segmentés, et comme il n’y a pas d’espace entre les mots chinois, notre script en bash ne peut malheureusement pas produire l’index et le bigame chinois.
Nous avons ainsi procédé d’autres mesures pour le traitement du corpus chinois.
-
Segmentation du chinois
Pour la segmentation du corpus chinois, nous avons utilisé le module Jieba de Language Python qui a été développé par MIT.

Grace à l’aide de Tao, nous avons pu segmenter notre corpus avec un petit script en Python3.
Pour installer le module Jieba:

Les fichiers d’entrée sont le ficher du dump-complet chinois et le fichier du contexte-complet:

Et voici le ficher txt de sortie:

-
Bigramme et index
Pour le traitement de bigramme et index de wordlist, j’ai écrit un autre script en bash en appelant le script de python de segmentation et de génération du bigramme.
Au début j’ai essayé la commande egrep -o “\w+”, mais l’expression “\w+” ne reconnait pas les tokens chinois, j’ai donc changé l’expression. Comme la majorité des mots non-grammaticaux en chinois sont composés de 2 caractères, j’ai donc utilisé l’expression ci-dessous pour générer une wordlist.
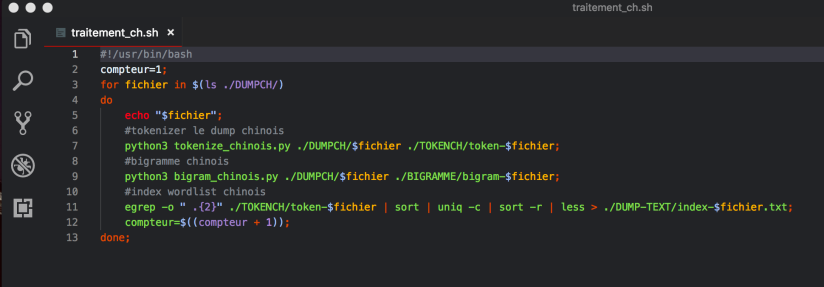
Et voici le résultat de l’index chinois:

Voici le bigramme généré par le code python:

