Nous repartons du script vu lors de la séance précedente pour enrichir notre tableau. Dans notre script d’origine, nous avons crée un tableau avec deux colonnes, la première contenant la numération des URLs et la deuxième les liens vers les pages de chacune d’elles. Nous avons amélioré le script pendant ces deux séances afin d’enrichir notre tableau.
Séance 17/10/2018
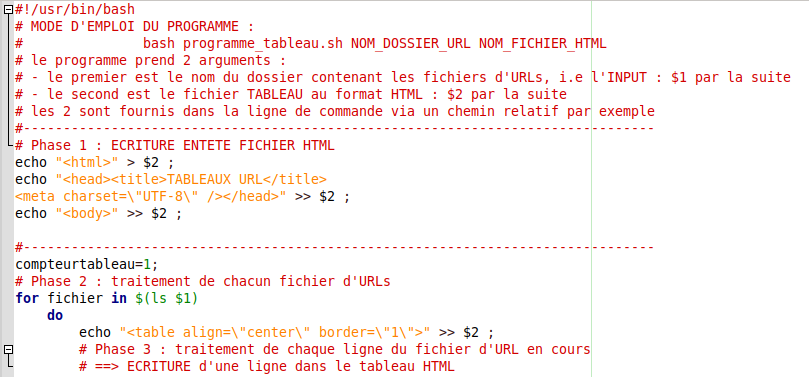
-Tout d’abord notre script doit traiter plusieurs fichiers d’URLs. Les solutions que nous avons adoptées sont les suivantes:
- Le script prend deux arguments – le premier est le nom du dossier qui contient les fichiers d’URLs.
- Créer une boucle for pour le traitement de chacun des fichiers d’URLs.
Pour l’instant, nous avons deux fichiers d’URLs dans notre dossier URLS, alors notre boucle for va s’executer deux fois.
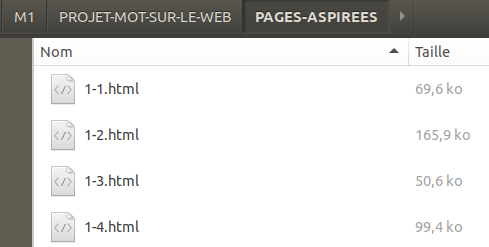
-Puis, nous avons ajouté une troisième colonne contenant la page aspirée pour chaque URL en utilisant la commande curl dans une boucle for pour chaque ligne dans chaque fichier d’URLs.
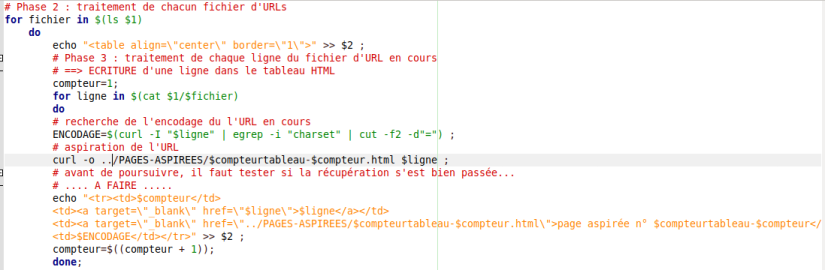
Les résultats de curl sont sauvegardés dans le dossier PAGES-ASPIREES et les fichiers html sont numérotés en utilisant les $compteurtableau (compteur de chaque fichier) et $compteur (compteur de chaque ligne dans chaque fichier).
-Ensuite, nous avons ajouté la quatrième colonne pour afficher l’encodage de chaque page. Nous avons utilisé la commande curl et nous avons également utilisé les expressions regulieres pour extraire l’encodage de chaque page.

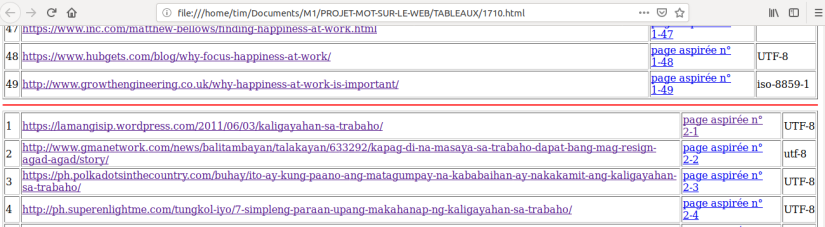
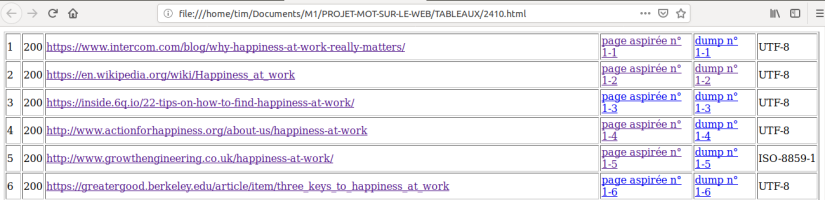
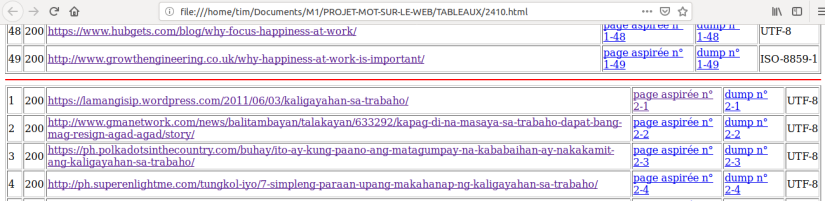
Voyons maintenant les résultats dans la page html générée par le script. Avec deux fichiers d’URLs, nous avons deux tableaux avec quatre colonnes. Sachant qu’il faut ajouter le traitement des encodages non UTF-8, la contrainte fixée est que toutes les sorties produites doivent être en UTF-8.

Séance 24/10/2018
Nouvelle scéance, nouvelles questions, nouvelles colonnes. Nous avons pris en compte les questions suivantes:
- Comment s’assurer que les traitements se déroulent bien?
- Comment extraire le texte brut de chacune des URLs?
- Comment faire en sorte que les sorties textuelles produites soient bien encodées en UTF-8?
-Tout d’abord nous avons appris que le code de retour 0 veut dire que la commande s’est déroulée correctement. Pourtant la commande curl peut avoir un code retour 0 même si la commande ne s’est pas bien déroulée. Pour s’assurer que le traitement de chaque URL se déroule corréctement, nous avons utilisé les requêtes HTTP. La communication entre les serveurs au niveau du réseau donne une réponse 200 si tout s’est bien passé. Nous avons ajouté une nouvelle variable code_sortie contenant le code retour de la connexion HTTP pour chaque URL.

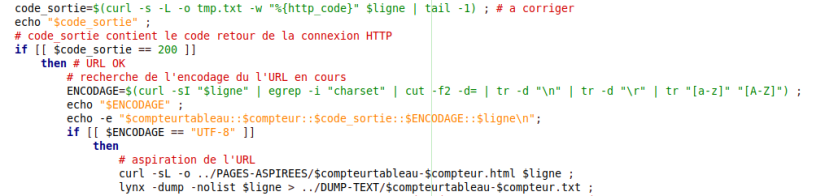
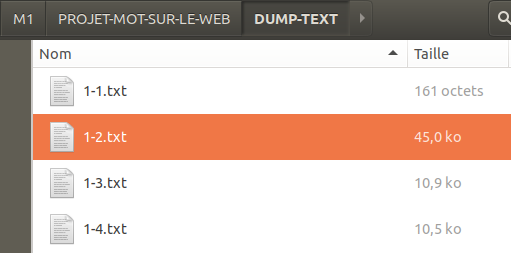
-Pour ce projet, nous travaillons sur du texte alors il est nécessaire d’avoir comme support un fichier texte, plutôt qu’une page html. Pour passer de l’un à l’autre, nous n’avons besoin que d’un élément: lynx, un navigateur en mode texte, par définition sans images. Les options –dump permet de ne récupérer que le contenu textuel de la page lue par lynx et –nolist permet de ne pas récupérer les liens hypertext.
Les résultats (en format texte brut) de notre commande lynx sont sauvegardés dans le dossier DUMP-TEXT. Voici le résultat dans l’arborescence de travail:
-Ensuite, il faut tester l’encodage de l’URL. Si l’encodage est de type UTF-8, le script execute l’aspiration des URLs, la récupération du contenu textuel puis les affiche dans le tableau, sachant qu’il faut encore ajouter le traitement des encodages non UTF-8.
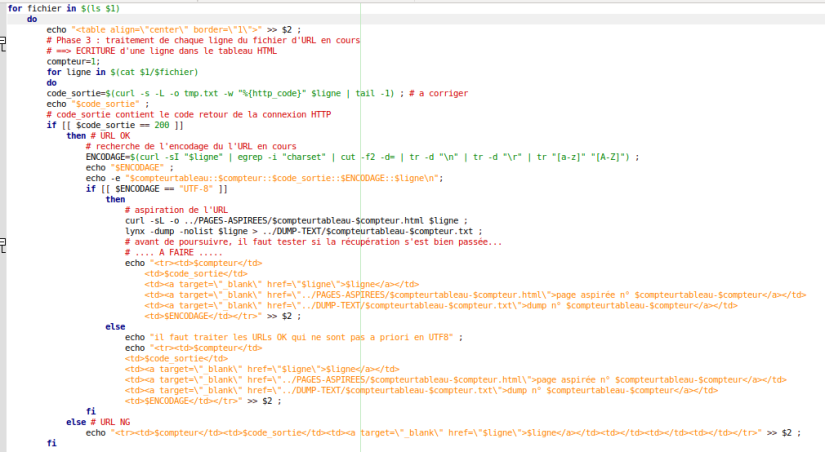
Voyons maintenant les résultats dans la page html générée par le script avec les nouvelles colonnes.
Voici un exemple d’une page dumpée, en format texte brut et sans liens hypertext.