Suite des procédures pour faire le tableau html que nous avons vus lors de la séance précédente, nous avons continué à enrichir le tableau en ajoutant des colonnes. Pour ce faire, des nouvelles notions sont introduites.
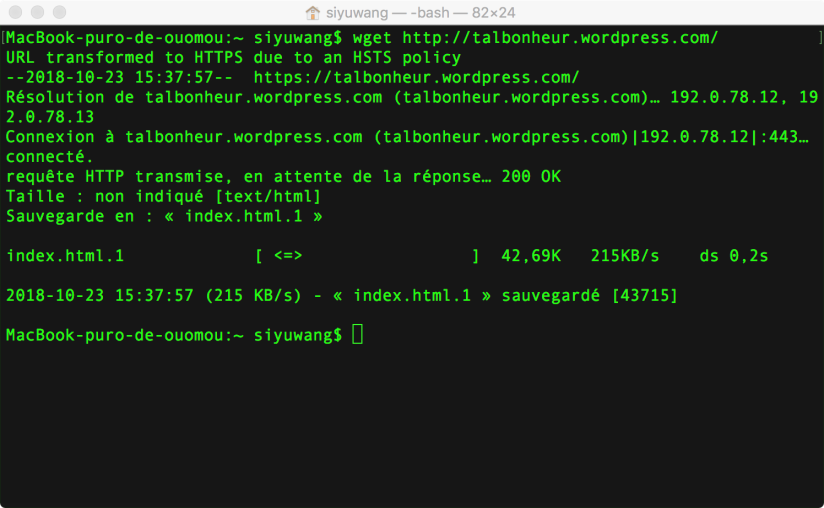
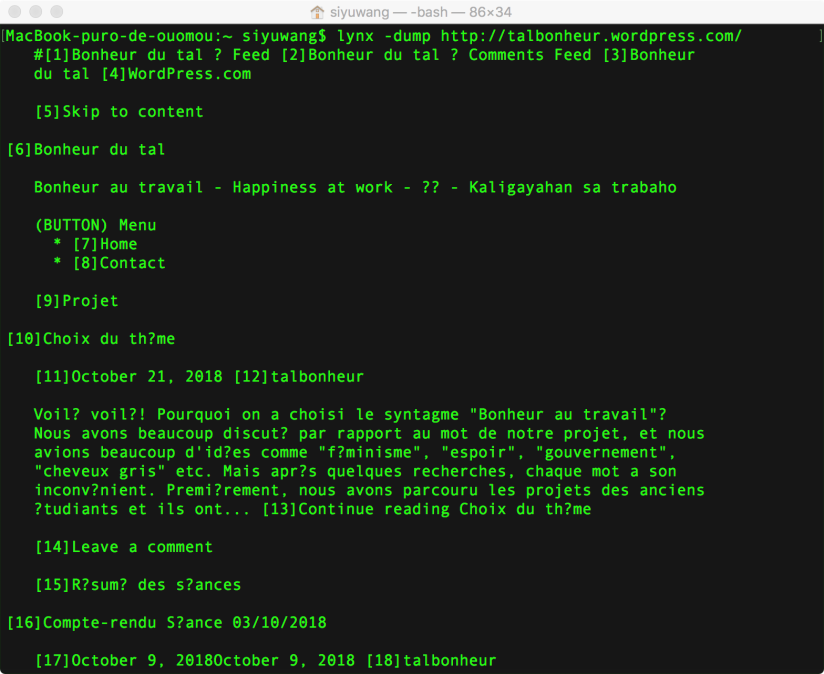
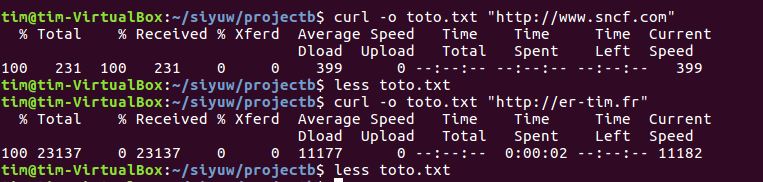
- wget, curl, et lynx sont des 3 commandes pour récupérer le contenu d’un site web.
- – wget
- –lynx -dump
- curl -o : récupérer le site web et -o en redirection pour sauvegarder
- file monfichier.txt : pour regarder l’encodage du fichier

- read: lire ce are l’utilisateur tape au clavier
- bash monficher.sh: pour exécuter programme écrit en bash
Pour construire le tableau html, nous avons besoins d’écrire nos codes dans un éditeur de text pour faciliter nos travaux. Et nous avons utilisé le boucle ‘for‘ pour numéroter chaque élément de notre liste url: compteur = 1; for élément in liste($cat fichier); do _____; compteur = $((compteur + 1)); done;
Tout d’abord on doit écrire un commentaire qui présente le fonctionnement du programme.

Puis on écrit l’entête du fichier html.

Ensuite on écrit le boucle pour numéroter chaque url.

Enfin on écrit la fin du fichier html.
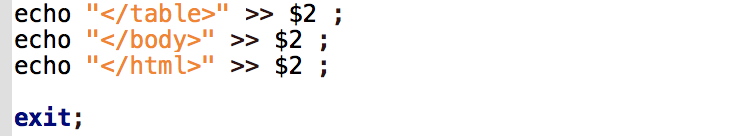
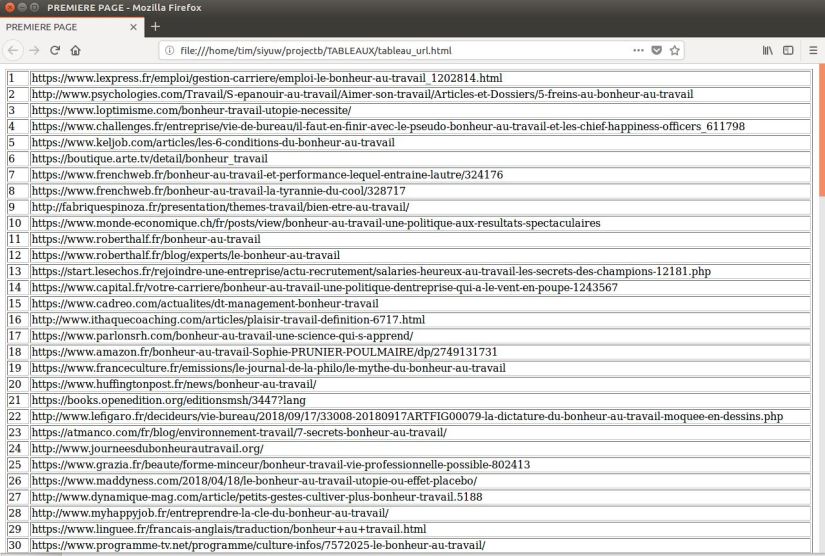
Étape suivante, on exécute le programme en indiquant les 2 arguments (le fichier txt qui contient la liste des urls ‘project_fr_clear.txt‘ et le fichier de sortie nommé ‘tableau_url.html‘), et on ouvre le fichier html avec le navigateur firefox.

Et voici le tableau du fichier html.